Was ist Customer Self-Service und welchen Mehrwert bietet er?
12.03.2021 |
Um ein Self-Service Angebot kommt heutzutage kein modernes Unternehmen mehr herum. Doch was...

In den letzten Jahren haben sich NoSQL-Datenbanken zu Standardlösungen entwickelt. Aber was ist der Unterschied zwischen SQL- und NoSQL-Datenbanken, wenn es um Schema Design und Beziehungen geht? Dieser Artikel soll dies beleuchten.
Im Gegensatz zu relationalen Datenbanken bieten NoSQL-Datenbanken die Möglichkeit, ein hohes Maß an Flexibilität, Einfachheit und Freiheit im Umgang mit Daten. Dabei gibt es verschiedene Typen von NoSQL-Datenbanken, welche sich in ihrem grundsätzlichen Lösungsansatz unterscheiden. Unabhängig vom Datenbanktyp sind Datenmodellierung und Schema Design wichtige Konzepte in jeder Anwendung.
NoSQL-Datenbanken wurden entwickelt, um das in relationalen Datenbanken verwendete Konzept von Zeilen und Spalten aufzubrechen. Es ist jedoch ein weit verbreiteter Irrglaube, dass NoSQL-Datenbanken keine Art von Datenmodell ermöglichen oder gar erzwingen. Das Entwerfen eines Schemas oder Datenmodells für NoSQL-Datenbanken ist auch hier ein zentrales Thema.
Ein Schema beschreibt dabei, wie die Daten innerhalb der Datenbank organisiert werden. Nach Auswahl einer NoSQL-Datenbank besteht die nächste Aufgabe zunächst darin, ein Schema für die ausgewählte Datenbank zu entwerfen.
Die Struktur von dokumentenbasierten Datenbanken unterscheidet sich von relationalen Datenbanken, welche Probleme mit Daten außerhalb des Spalten- und Zeilenmodells haben. Anstelle von Tabellen und Zeilen werden bei dokumentenbasierten NoSQL Datenbanken Sammlungen und Dokumente verwendet, wobei jedes Dokument eine einzelne JSON-Repräsentation darstellt, die einfach oder verschachtelt sein kann. Sie passen sich flexibel an eine Vielzahl von Datentypen, wechselnde Anwendungsanforderungen und Datenmodelle an.
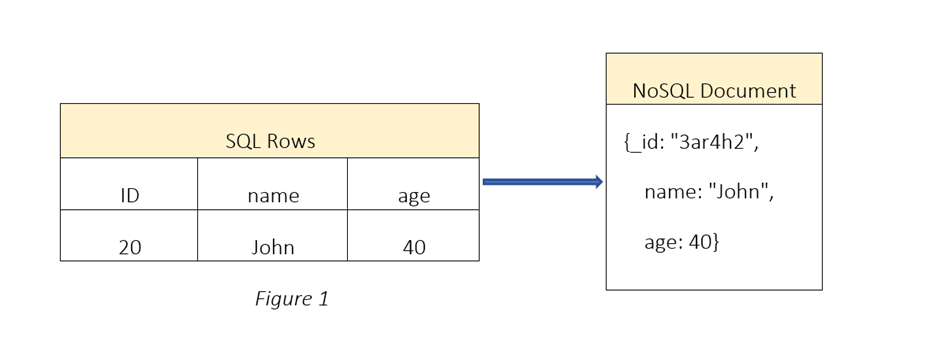
Da NoSQL mit Sammlungen (Collections, „Tabelle“) und Dokumenten (Document, Datenobjekt) arbeitet, ist es wichtig, die Konzepte der Normalisierung und Denormalisierung zu verstehen. Diese beiden Ansätze definieren, wie Daten in NoSQL-Datenbanken gespeichert werden.
Normalisierung - bedeutet, dass die Daten in mehreren Sammlungen gespeichert werden. Beziehungen zwischen Daten erfolgen über Referenzen – dieser Ansatz ist aus der relationalen Welt bekannt. Vorteil: die Daten werden einmal definiert und lassen sich so leichter aktualisieren. Wenn es um das Lesen von Daten geht, ist der Nachteil der Normalisierung offensichtlich. Wenn Daten aus mehreren Sammlungen abgerufen werden sollen, müssen mehrere Abfragen durchgeführt werden. Dies hat zur Folge, dass der insgesamt Lesevorgang langsamer ist.
Denormalisierung - Speichert eine große Menge von verschachtelten Daten in einem Dokument. Dieses Modell bietet eine bessere Leseleistung, ist aber langsamer bei Einfügungen und Aktualisierungen. Diese Methode der Datenspeicherung nimmt zudem mehr Speicherplatz in Anspruch, da Daten redundant gespeichert werden.
Die dokumentenbasierte Schemamodellierung ist für jedes Datenelement auf zwei Arten möglich. Sie können die Daten entweder direkt einbetten oder auf andere Daten verweisen. Betrachten wir die Vor- und Nachteile beider Optionen bei der Schemamodellierung.
Bei dokumentenbasierten Datenbanken bedeutet Embedding die Denormalisierung von Entitäten durch Einbettung einer Entität in eine andere als Subdokument. In der folgenden Abbildung wird das Dokument aus fünf Entitäten (rechte Seite) erstellt. Die fünf Entitäten werden denormalisiert und in ein einziges Dokument verschachtelt.

The embedding approach has some advantages and disadvantages which are considered in the next steps.
In dokumentenbasierten Datenbanken gibt es eine Größenbeschränkung für Dokumente. So ist beispielsweise beim Anbieter MongoDB die Größe eines einzelnen Dokumenteneintrags auf 16 MB begrenzt. Auch das Embedding-Level der Subdokumente ist ein weiterer relevanter Aspekt. MongoDB unterstützt hier zum Beispiel die Einbettung von Daten bis zu einer Tiefe von 100. Wenn viele Daten in ein einzelnes Dokument eingebettet werden sollen, ist dieser Faktor zwingend zu berücksichtigen.
Der Embedding-Ansatz bietet unter vielen Umständen das beste Verhalten und gewährleistet Datenkonsistenz. Jedoch ist in einigen Fällen auch ein normalisiertes Modell die bessere Lösungsvariante. Ein offensichtliches Argument für die Normalisierung einer Datensammlung in mehrere Sammlungen ist die damit verbundene Flexibilität bei der Ausführung von Abfragen.
Die Referenzierung eines Dokuments in einem anderen Dokument unter Verwendung einer so genannten Objekt-ID ist bei diesem Ansatz eine gängige Methode und ähnelt dem Konzept der Primär-/Fremdschlüssel-Beziheung, wie sie aus relationalen Datenbanken bekannt ist. Auf diese Weise ist es möglich, Daten aufzuteilen und Beziehungen zwischen Daten herzustellen. In der nachfolgenden Abbildung wird die Sammlung normalisiert und in zwei Sammlungen (Seminar und User) mit dem Verweis auf die Beziehung aufgeteilt.
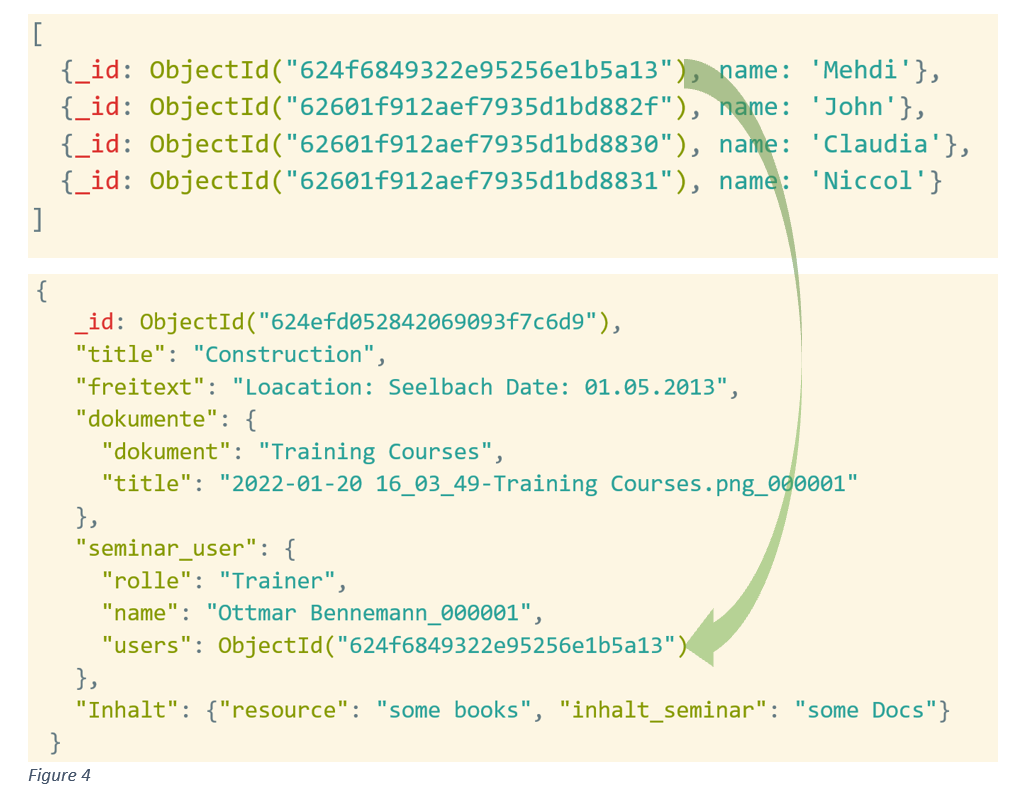
Beim Lesen und Abrufen der Daten gibt es einige Methoden, die der JOIN-Funktion in SQL ähneln und es ermöglichen, die Sammlungen in einem Ergebnis zusammenzuführen.
Zum Abrufen der Daten in referenzierten Dokumenten sind mindestens zwei Abfragen oder der Aufruf einer dedizierten Funktion (populate/lookup (join)) erforderlich.
Es wurden zwei Ansätze zum Schemadesign in dokumentenbasierten Datenbanken betrachtet, aber es stellt sich immer noch die Frage, welcher Ansatz in welchen Anwendungsfällen verwendet werden sollte.
Wie Daten in dokumentenbasierten Datenbanken modelliert werden, hängt ganz von den Datenzugriffsmustern der Anwendung und dem Businessplan ab. Daten sollten so strukturiert sein, dass sie zu den Abfragen und Aktualisierungen der Anwendung passen. Dennoch gibt es einige allgemeine Hinweise und Empfehlungen zur Modellierung, welche im Folgenden erläutert werden.
Die Modellierungsempfehlung wird maßgeblich von der Kardinalität und dem Beziehungstyp zwischen Dokumenten Kollektionen und Dokumenten bestimmt:
Für fachkundige Unterstützung bei Ihren individuellen Digitalisierungsvorhaben, entdecken Sie USU Digital Consulting. Wir helfen Ihnen bei der schnellen Umsetzung mit Beratung, Entwicklung, Betrieb und Support.
Quellen:
https://www.arangodb.com/docs/stable/data-modeling-concepts.html
https://www.guru99.com/nosql-tutorial.html
https://www.mongodb.com/docs/manual/core/data-modeling-introduction
https://dev.to/damcosset/mongodb-normalization-vs-denormalization
Um ein Self-Service Angebot kommt heutzutage kein modernes Unternehmen mehr herum. Doch was...
Customer Service Digitale Transformation Digitale Trends
Warum Social Selling die Zukunft gehört und das „Tante-Emma-Prinzip“ des personalisierten Service...
Cloud Monitoring Hybrid Cloud Computing
Galt es vor Jahren noch, einfache Client-Server-Strukturen zu überwachen, stellt vor allem das...