In recent years, a few different applications called NoSQL databases have gained popularity. But what is the difference between SQL and NoSQL databases when it comes to Schema Design and Relationship? This article describes Schema and relationships in document-based NoSQL databases.
By moving away from relational databases, NoSQL databases offer a way to work much more freely with data and provide a high degree of flexibility and simplicity. There are several types of NoSQL databases. Regardless of the database type, data modelling and schema design are important concepts in any application. However, it is sometimes said that NoSQL is schema-less for data modelling, but this is a misconception. This article focuses on schema design in domain of the document-based NoSQL databases.
Schema Design and Relationship in NoSQL Document-based
NoSQL databases were developed to get away of the rows and columns used in relational databases. However, it is a common misconception to believe that NoSQL databases do not enforce any kind of data model. Designing a schema or data model for NoSQL is an important issue in any application. A schema is a useful description of how the data should be organized inside the database. After selecting a NoSQL database, the next task is to design a schema for the selected database.
Normalization (referencing) or denormalization (embedding) of data?
Since NoSQL works with collections and documents, it is important to understand the concepts of normalization and denormalization. These two approaches define how data is stored in NoSQL databases.
Normalization - means that data is stored in multiple collections by referencing between them. Data is defined once and makes it easier to update. When it comes to reading data, the disadvantage of normalization is obvious. If you want to retrieve data from multiple collections, you need to perform multiple queries. As a result, the reading process is slower.
Denormalization - Stores a large amount of nested data in a document. This model performs better reads but is slower for inserts and updates. This method of data storage takes up more memory.
Data structure in NoSQL Document-bases databases
The structure of document-based databases differs from relational databases, which have problems with storing data outside columns and rows. Instead of tables and rows, NoSQL document-based uses collections and documents, each document is a single json file which can be simple or nested json. They adapt in a flexible way to a wide variety of data types, changing application needs and data models.
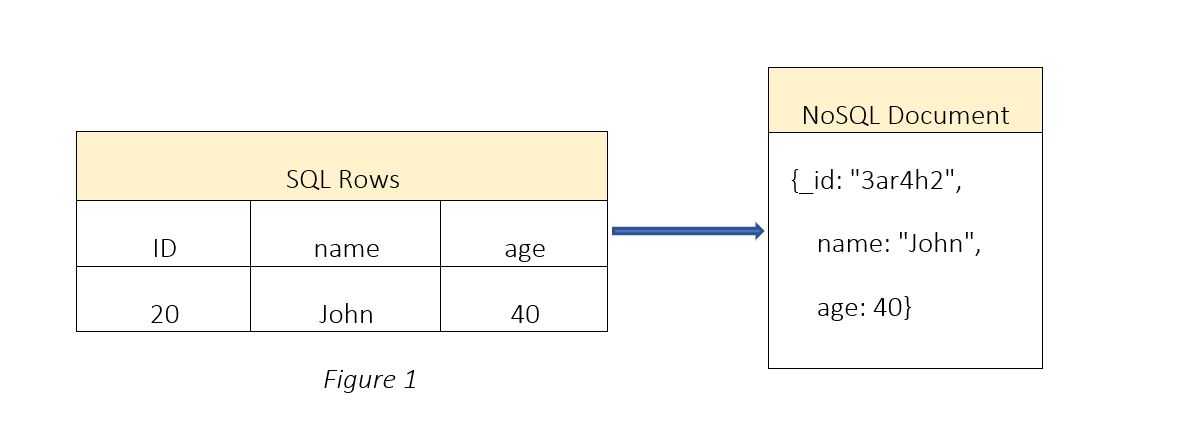
Embedding or referencing; which data modelling approach is better in document based NoSQL databases?
Document-based schema modelling is possible in two ways for every piece of data. You can either embed the data directly or reference it another data. Let's consider the pros and cons of both option in the schema modelling.
Embedding approach
For Document based databases, nesting, or embedding means to denormalizing entities by nesting one entity into another as a subdocument. In Figure 2 the document is created from five entities (Figure 3). The five entities are denormlized to be nested in one single document.

The embedding approach has some advantages and disadvantages which are considered in the next steps.
Pros
- One can retrieve all relevant information in a single query.
- Avoid implementing joins in application code or using populate/lookup (Join).
- Update related information as a single atomic operation. By default, all CRUD operations on a single document are ACID compliant.
Limitations
There is a document size limit in document-based databases - for example MongoDB has the limitation of a 16-MB of a single document entry. Also, embedding level of the subdocuments is another issue that must be taken into account. For instance, MongoDB supports embed data until a depth of 100. If embedding much data inside a single document, one should consider this limitation.
Referencing approach
Embedding is the approach that ensures the best behaviour and data consistency under many circumstances. But in some cases, having a normalized model performs better. In fact, one obvious argument for normalizing your data collection into multiple collections is the flexibility it provides in executing queries.
Referencing the document and collection in another document using the object ID in this approach is a common method and is more like a primary/foreign key feature known from relational databases. In this way, it is possible to split data and establish relationships between data. In Figure 4, the data is normalized and split into two collections with the reference of the relationship. When reading and retrieving the data, there are some methods similar to the JOIN function in SQL.
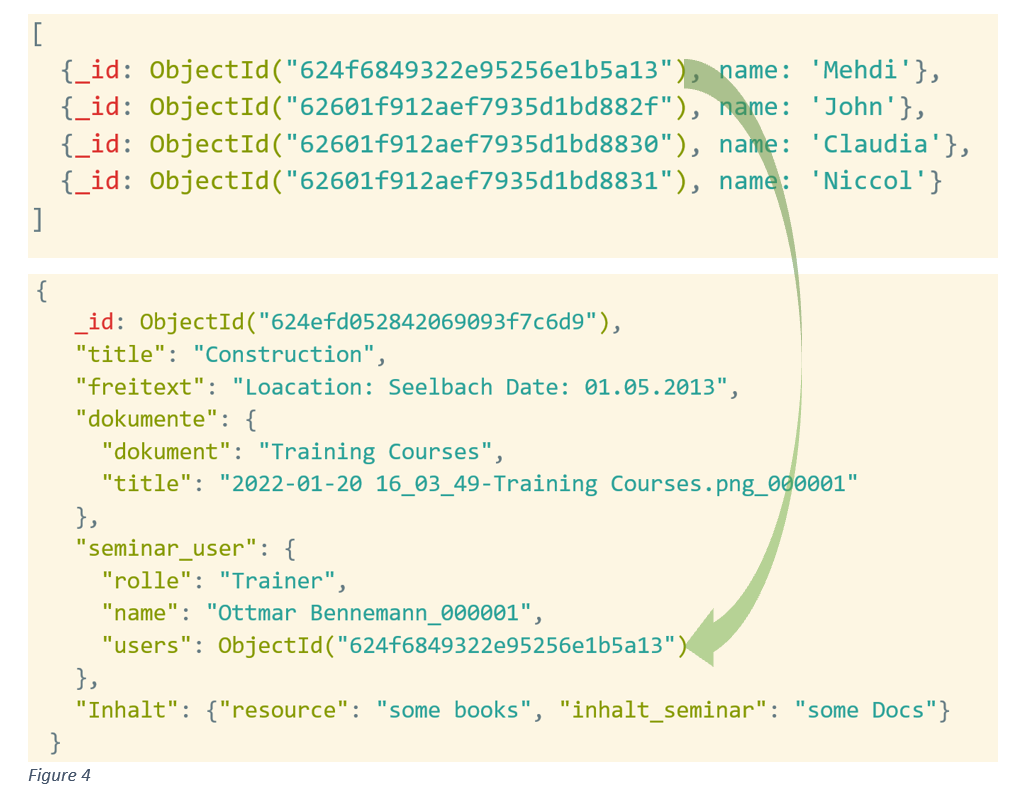
The referencing approach also has some advantages and disadvantages which are considered in next.
Pros
- With splitting up data, one will have smaller documents.
- Selective retrieval of data, since in most queries it is not necessary to fetch all data of a collection
- Avoids duplication of data.
Limitations
For retrieving the data in the referenced documents, at least two queries or the function populate/lookup (join) required to get the data.
So, we have seen the approaches towards the schema design in document-based databases, but still there is a question; which approach is used in a specific use case?
Conclusion
In document-based databases, how you model your data, depends entirely on your applications data access patterns and the business plan. You want to structure your data to match the ways that your application queries and updates it. However, still there are some general recommendations for the related data which may be considered as below.
General recommendation for schema modelling and relationships:
- One to one relationship: embedding model preferred
- One to few relationships: embedding model preferred
- One to many relationships: referencing model preferred
- Many to many relationships: referencing model preferred
- Favour embedding unless there is a compelling reason not to
- Needing to access an object on its own is a compelling reason not to embed it
- Avoid joins and populate (lookups) if possible, but don't be afraid if they can provide a better schema design
- Arrays should not grow without bound. If there are more than a couple of hundred documents on the many sides, don't embed them; if there are more than a few thousand documents on the many sides, don't use an array of ObjectID references.
For expert guidance with your individual digitalization projects, explore USU Digital Consulting.
We're here to help you implement them more quickly with consulting, development, operation and support.
References:
https://www.arangodb.com/docs/stable/data-modeling-concepts.html
https://www.guru99.com/nosql-tutorial.html
https://www.mongodb.com/docs/manual/core/data-modeling-introduction
https://dev.to/damcosset/mongodb-normalization-vs-denormalization
