Digital Consulting Pega PegaTime
Pega Upgrade in 9 Schritten
02.05.2024 |
Regelmäßige Upgrades der Pega-Software sind wichtig, um von den zahlreichen Vorteilen und...

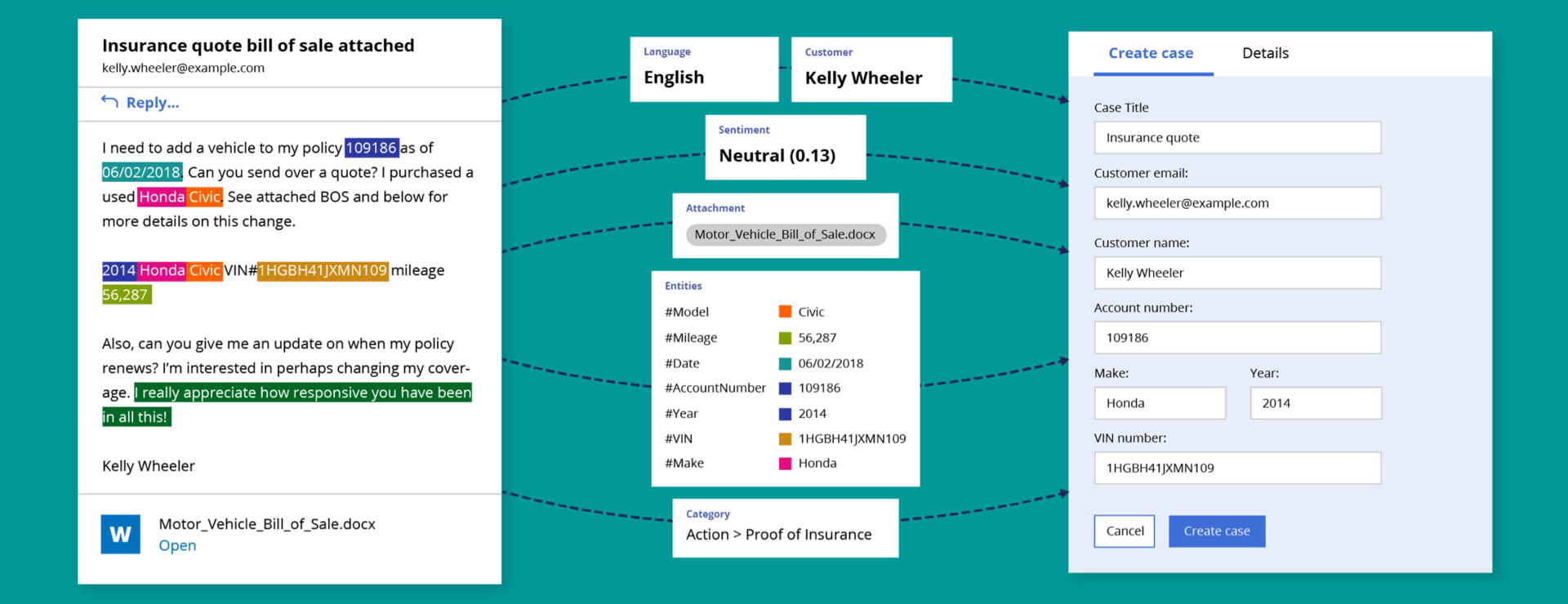
Pega bietet eine leistungsstarke Textextraktionsmethode zur Analyse von E-Mail-Inhalten und Kategorisierung von Textdaten. Die Text Extraktion ermöglicht die Identifizierung von benannten Entitäten in Textdaten und deren Zuordnung zu vordefinierten Kategorien, wie beispielsweise Organisationen, Orten, Personen, Mengen oder Werten. Durch die Nutzung der maschinellen Lernfunktionen der Pega-Plattform können Modelle zur Entitätsextraktion erstellt werden, die in der Lage sind, benannte Entitäten zu erkennen.
Durch die Erstellung von Modellen für die Entitätsextraktion zur Erkennung von Schlüsselwörtern und Phrasen können automatisch Fälle erstellt, Formulare ausgefüllt oder Aufträge weitergeleitet werden. Jedes Entitätsextraktionsmodell klassifiziert Schlüsselwörter und Phrasen wie Personennamen, Orte, Organisationen usw. in vordefinierte Kategorien, die als Entitätstypen bezeichnet werden.
![]()
Um jeden Entitätstyp in einem unstrukturierten Text zu identifizieren, werden verschiedene Erkennungsmethoden kombiniert. Mithilfe von Entitätstypen können komplexe Modelle für die Entitätsextraktion erstellt und verwaltet werden, beispielsweise für Datum oder Datum-Zeit. Darüber hinaus unterstützen Entitätstypen die Verwaltung von verschachtelten Entitäten. Zum Beispiel kann eine Adresse verschachtelte Entitätstypen wie Land, Bundesland, Provinz, Postleitzahl, Straße usw. enthalten.
Neben der Keyword-basierten Methode und der maschinellen Lernen Methode können hier zusätzlich RUTA-Skripte zum Identifizieren von Entitäten verwendet werden. Das Apache UIMA RUTA-Skript ist eine regelbasierte Skriptsprache, die zur Erkennung von Mustern in Texten verwendet wird. Dabei werden Anmerkungen in Verbindung mit Bedingungen eingesetzt, um die Muster zu definieren. Sobald ein Muster übereinstimmt, wird die entsprechende Aktion ausgeführt. Zusätzlich können reguläre Ausdrücke im Skript verwendet werden, um die Muster zu finden.
Bei der Text Extraction steht im Vergleich zum Topic-Modell nur der Conditional Random Fields (CRF) Algorithmus zur Verfügung. Die Wahl zwischen Keyword-Listen und Machine Learning sowie die Erkennung von Entitäten mittels RUTA-Skript sind mögliche Optionen. Im Gegensatz zur Topic Detection werden alle Entitäten in einer Liste gespeichert, und der F-Score gibt Auskunft über die Leistung des Modells.
-1.jpg?length=400&name=usu_dc_pega-reihe_blog-header_1920x1080px%20(1)-1.jpg)

CRFs sind ein wichtiger Typ von Machine-Learning-Modellen, insbesondere im Natural Language Processing. Sie werden für Textsegmentierung, -kennzeichnung und die Erkennung benannter Entitäten wie Personen und Organisationen eingesetzt. Im Vergleich zu einfacheren Modellen wie Hidden-Markov-Modellen können CRFs eine breitere Palette von Merkmalen und Kontexten berücksichtigen. Der Algorithmus beschreibt sich durch die Bedingte Wahrscheinlichkeit P(y│x) unter Verwendung von Merkmalsfunktionen, die Abhängigkeiten zwischen Eingabe- und Ausgabevariablen modellieren. CRFs sind überwachte Lernmodelle und können an spezifische Anforderungen angepasst werden.
CRFs verwenden Merkmalsfunktionen, um Abhängigkeiten zwischen Eingabe- und Ausgabevariablen zu modellieren. Diese Funktionen nutzen Kontextinformationen, um präzise Vorhersagen zu treffen, und ermöglichen die Integration von domänenspezifischem Wissen. Die Merkmalsfunktionen sind entscheidend für die Skalierbarkeit und Effizienz des CRF-Modells. Sie dienen dazu, relevante Kontextinformationen zu erfassen und in die Modellierung einzubringen, um eine bessere Repräsentation der Daten zu erzielen.
Eine Merkmalsfunktion f(x,i,y_i,y_(i-1)) kann durch eine bestimmte Bedingung entweder den Wert 1 oder 0 annehmen. Dies ermöglicht die Integration verschiedener Fragestellungen und erhöht die Effektivität und Genauigkeit der Analyse und Vorhersagen.
Die Flexibilität von CRFs im Modellentwurf, ihre Anpassungsfähigkeit an spezifische Anforderungen und die Berücksichtigung von Kontextinformationen machen sie zu einem leistungsfähigen Werkzeug in der Text Extraction.
.jpg?length=400&name=only-ppt_high-five%20(3).jpg)

Um von den Machine-Learning-Modellen in Pega präzise Vorhersagen zu erhalten, ist eine effektive Vorbereitung der Trainingsdaten unerlässlich. Für die Text-Extraction-Modelle werden CSV-, XLS- oder XLSX-Dateien verwendet, die spezifischen Anforderungen entsprechen müssen.
Das Text-Extraction-Modell erfordert eine Datei mit zwei Spalten: "Content" und "Type". In der "Content"-Spalte werden die E-Mail-Daten eingetragen, während die "Type"-Spalte angibt, ob es sich um Trainings- oder Testdaten handelt. Die Daten in der "Content"-Spalte werden nach einem spezifischen Muster aufbereitet, wobei Entitäten durch Markierungen wie <START:...> und <END> definiert werden. Diese Entitäten, wie z.B. "Bankverbindung_aendern", werden später auf Variablen in Pega gemappt und ermöglichen die automatische Ausfüllung von Feldern.

Digital Consulting Pega PegaTime
Regelmäßige Upgrades der Pega-Software sind wichtig, um von den zahlreichen Vorteilen und...
Digital Consulting Machine Learning Pega
Pega bietet verschiedene Möglichkeiten der Textverarbeitung. Dies kann vor allem im Kundenservice...
Kunden effizient und persönlich zu erreichen, ist heute wichtiger denn je. Ein Unternehmen, das...