Systems Monitoring in der öffentlichen Verwaltung
05.08.2021 |
Digitale Services in der öffentlichen Verwaltung? In Deutschland? Das ist schwer vorstellbar. Denn...

NEED FOR SPEED. Jede Millisekunde zählt. Zumindest bei geschäftskritischen Web-Services wie beispielsweise Online-Banking oder Online-Shops. 100 Millisekunden Verzögerung der Antwortzeit kosten Amazon 1 Prozent des Umsatzes, meinte einmal Greg Linden, der Erfinder des Empfehlungs-Systems bei Amazon. Werden Produkte nicht sofort geladen, Suchergebnisse nicht sofort angezeigt, brechen viele Onlinekäufer den Einkaufsprozess ab und bleiben dauerhaft fern – eine denkbar schlechte User Experience, ein Worst Case-Szenario. Verfügbarkeit und Performance sind die beiden erfolgskritischen Zielgrößen, für deren Überwachung heute Monitoring-Systeme sorgen. Aber neben diesen Basis-Zielen können professionelle Monitoring-Anwendungen sehr viel mehr. Der folgende Blogbeitrag zeigt, wie Sie mit aktiver Überwachung in Kombination mit Capacity und Alarm Management die Einhaltung von SLA´s und einen wirtschaftlichen IT-Betrieb garantieren können – vor allem angesichts komplexer hybrider IT-Landschaften. Ihre Investitionen in entsprechende Technologien rechnen sich bereits innerhalb weniger Monate.
Ein umfassendes und einheitliches Monitoring („Umbrella-System“) ist ein wichtiger Schlüssel, um die Komplexität heutiger hybrider Umgebungen zu beherrschen. Geschäftstransaktionen, Applikationen und die Infrastruktur müssen souverän gesteuert werden – auch in virtualisierten, containerisierten, Cloud-basierten und/oder lokalen IT-Umgebungen. Für deren Überwachung werden in der unternehmerischen Praxis häufig mehrere, nicht integrierte Lösungen eingesetzt, z.B. SAP, Nagios, Splunk, Automic, Oracle Enterprise Manager oder weitere Datenbank- bzw. Netzwerktools. Nicht selten finden sich bei großen, international agierenden Organisationen bis zu 20 solcher isolierten Überwachungssysteme, gerne auch über den gesamten Erdball verteilt. Diese sind meist – analog zur Ausweitung der IT-Infrastruktur – historisch gewachsen.
In der Praxis führt die Konstellation parallel laufender Inselsysteme nicht nur zu signifikanten Mehr-Aufwänden für den redundanten Betrieb mehrerer Tools. Der im Ernstfall so wichtige systemübergreifende 360-Grad-Blick ist bei diesem „Silo-basierten“ Überwachungsansatz nicht gegeben. Die Folgen können gravierend
sein. Denn die Ursachenfindung gestaltet sich in der Regel schwierig und ist sehr zeitraubend. Die Störungsbehebung verzögert sich, da die einzelnen System-Administratoren zunächst ihre eigenen Ansichten überprüfen. Außerdem lässt sich der Schweregrad einer Störung und die Auswirkung auf die Kunden bzw.
das Business – isoliert betrachtet – meist nicht richtig einschätzen. Ein ganzheitliches Umbrella-Monitoring reduziert Ihre direkten und indirekten Aufwände und hat u.a. positive Effekte für folgende Aspekte:
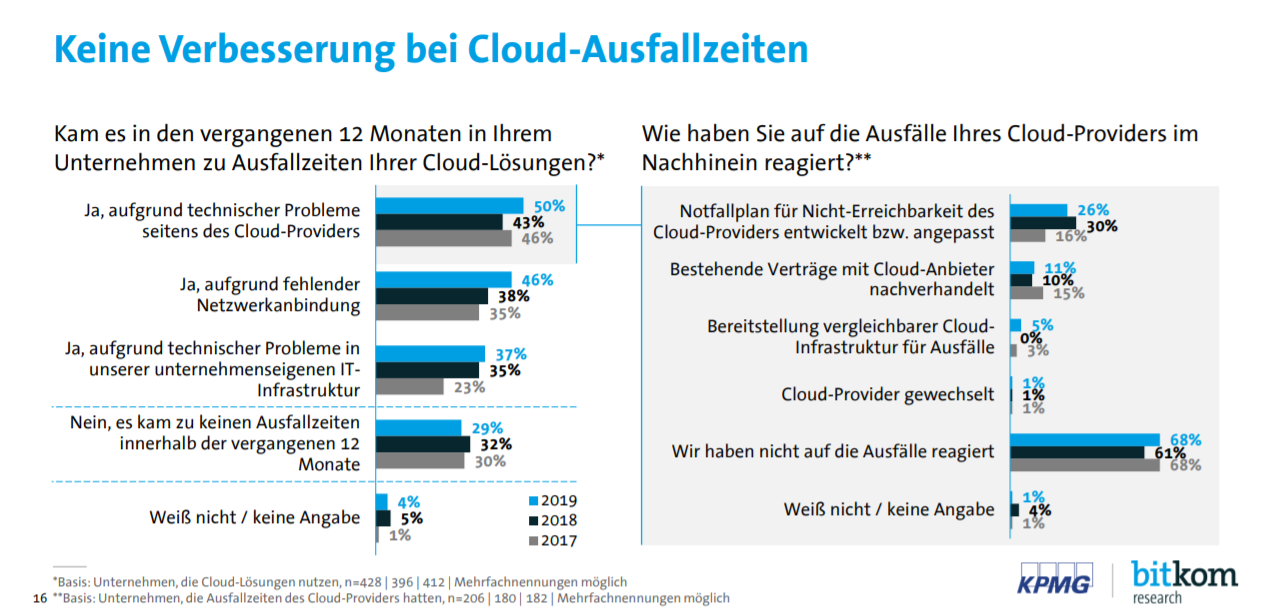
Abb.1: Beispiel Cloud: Die Hälfte der Unternehmen beklagt Ausfallzeiten aufgrund technischer Probleme bei Cloud-Anbietern
Ganzheitlich wird das Erlebnis perfekt funktionierender Anwendungen nur am „Point of Customer“, also vor dem Bildschirm. Und dafür sorgt das ergänzende E2E-Monitoring. Die Erfahrung zeigt, dass die Überwachung einzelner technischer Komponenten eines IT-Service alleine nicht ausreicht. Denn Datenbanken oder Webserver können reibungslos funktionieren, die darauf aufgebaute Applikation jedoch nicht. Die Ursachen hierfür
sind mannigfaltig, z.B. eine schlecht programmierte Oberfläche oder langsame Ladezeiten nach einem Software-Update. Daher ist die Überwachung des gesamten Spektrums physischer, prozessualer und anwendungsbezogener Daten notwendig, die über mandantenfähige Dashboards aggregiert und zentral dargestellt werden. Auf einen Blick lassen sich damit in Echtzeit die Verfügbarkeit der Systeme und die Performance der Verbindungen aus der Sicht des Endbenutzers anzeigen.
Störfälle proaktiv vermeiden
Eine regelmäßige Qualitätsprüfung erlaubt es, entstehende Schwachstellen und Systemengpässe vorausschauend zu identifizieren, z.B. sich aufbauende hohe Ladezeiten. Es ist wichtig, nicht nur die SLAs zu überwachen. Vielmehr sind alle Daten zu nutzen, die die End-to-End-Überwachung über die gesamte Delivery Chain erfassen. Werden kritische Schwellwerte erreicht, alarmiert das System automatisch die zuständigen Experten. Im Idealfall leiten diese proaktiv Gegenmaßnahmen ein – noch bevor die Endanwender betroffen sind.
Service Level Monitoring:
Das E2E-System gleicht reale Performance-Daten mit den Kennzahlen ab, die in IT-Services definiert sind. Dies macht transparent, ob vertraglich vereinbarte Service-Level-Agreements (SLAs) eingehalten oder verletzt wurden. SLA-Verstöße umfassen Einnahme- oder Produktivitätsverluste, rechtliche Sanktionen, den Verlust von Markenwerten und Stammkunden – der Gesamtschaden kann leicht in die Millionen gehen. E2E-Monitoring unterstützt bei der Vermeidung von SLA-Verletzungen und daraus resultierenden Vertragsstrafen. Auf der anderen Seite dient E2E-Monitoring Service-Kunden als Instrument zur Qualitätssicherung, das die Leistungen von Outsourcern oder Serviceprovidern validiert. Gerade bei der effektiven Überwachung von Drittanbieter-Diensten kommen klassische Monitoring-Systeme an ihre Grenzen. Ein modernes SLA-Management benötigt zwingend die spezifischen Überwachungsmesspunkte für die Analyse von Problemen bei SaaS-, DNS- oder API-Services.
Aber nicht nur im Ernstfall sparen Monitoring-Systeme Ihrem Unternehmen bares Geld – auch bei Alltagsproblemen unterstützen sie dabei, den IT-Betrieb möglichst wirtschaftlich zu gestalten. Gartner beziffert z.B. die Kosten für unnötige Cloud-Ressourcen weltweit auf 14,1 Milliarden US-Dollar – und 2021 sollen es bereits 21 Milliarden sein. Damit sind über ein Drittel der weltweit getätigten Aufwendungen für Cloud-Ressourcen unnötig. Da Cloud-Anwendungen von den Fachabteilungen häufig nach dem „All you can eat-Prinzip“ bestellt, aber nicht oder nur zum Teil konsumiert werden, ist ein Blick auf die Nutzung wichtig, bei dem Monitoring- und Alarmierungs-Systeme unterstützen.
Anhand definierter Schwellenwerte identifiziert die automatische Überwachung und Berichterstattung bestimmte Cloud-Systeme als "betriebsbereit, aber untätig". Da ein "up and running" permanente Zahlungen an Cloudanbieter wie z.B. AWS impliziert, werden die Verantwortlichen über diese Situation informiert. Die Mitteilung liefert auch verschiedene alternative Vorschläge, wie die Situation verbessert werden kann. Diese Vorschläge werden automatisch vom System generiert. Die Optionen lauten z.B.: "Beginnen Sie mit der Nutzung wie geplant", "Lassen Sie uns den Dienst auf ein kleineres/günstigeres System verkleinern, bis Sie die bestellte Rechenleistung wirklich benötigen" oder "Lassen Sie uns das System beenden, um die Zahlungen an AWS zu einzusparen (und ein neues System beantragen, wenn Sie es wirklich benötigen)". Die Meldung geht ggf. auch an den Kostenstellenleiter, der aus der Kostenzuordnung sofort weiß, welche Kosten für diesen Service anfallen. Die Eskalationsstufe sieht systemseitig die automatisierte Abschaltung des Rechners vor, wenn bestimmte Kriterien erfüllt sind.
Über das reine Monitoring hinaus stellt das Capacity Management sicher, dass die vorgehaltenen IT-Kapazitäten den aktuellen und künftigen Anforderungen gerecht werden. Ein integrierter „Überwachungsschirm“ über alle Performancedaten ermöglicht deren Zusammenführung und Verdichtung
in einer einheitlichen Struktur und Sichtweise. Einerseits lassen sich die Kapazitäten bestimmter, für Services, Systeme und Applikationen benötigter Ressourcen bzw. Komponenten messen, andererseits erlauben automatisierte Datenanalysen und das Einbeziehen von Vergangenheits-Werten die Priorisierung, Optimierung und Planung von Kapazitäten auf Basis von Prognosen und Trends. Übersichtliche Dashboards für verschiedene Rollen, z.B. Service Owner, Fachabteilungen, Leitstände oder Management, liefern die jeweils benötigte Information auf einen Blick. Und bei drohenden Kapazitätsengpässen oder sonstigen konkreten Problemen greift das Alarmmanagement. So hält man die Balance zwischen Wirtschaftlichkeit und Leistungsfähigkeit – auch beim bedarfsgerechten Einkauf von externen Kapazitäten.
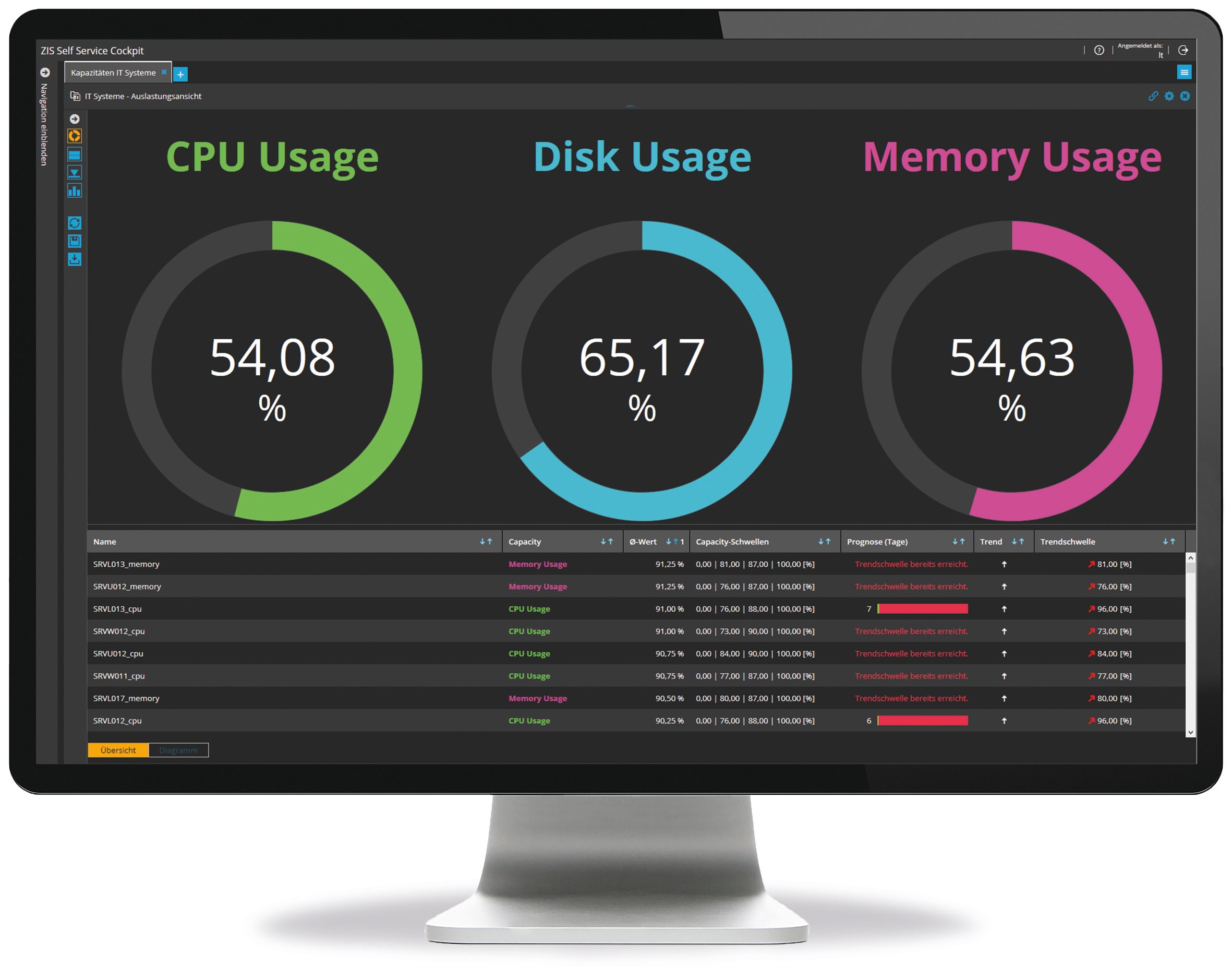
Abb.2: Dashboard Capacity Management
Eine der wesentlichen Vorteile eines übergreifenden zentralen Monitoring-Systems liegt in der Filterung und Klassifizierung von Informationen über auftretende Störungen. Durch eine integrierte Ticket-Korrelation wird die Fülle der generierten Daten mit Blick auf die relevanten Informationen automatisch bewertet. Aus der großen Menge von Ereignissen (Events) werden nur die wirklich wichtigen Tickets zusammengefasst und zur Bearbeitung an den Service Desk weitergeleitet. Dieser erhält auch zusätzliche relevante Informationen zu den betroffenen Cis, dem Fehler etc. Dadurch lassen sich nicht nur die Tickets um etwa ein Drittel reduzieren – auch die Qualität der Tickets steigt erheblich und die Bearbeitungszeit wird reduziert.
Folgende konservative ROI-Berechnung ist demnach realistisch:
Bei einer Ticketanzahl von ca. 60.000 pro Jahr (5.000 pro Monat) lassen sich durch die oben genannten Korrelations-Systeme etwa 18.000 Tickets einsparen. Setzt man die o.g. Ticket-Kosten von 15 € pro Ticket an, summiert sich das Einsparpotenzial pro Jahr auf mindestens 270.000 €. Somit amortisiert sich die Investition in ein übergreifendes Monitoringsystem mit einem Event-Korrelations-Modul bereits nach kurzer Zeit.
Sind Ihre Services 100%ig verfügbar? Beheben Sie auftretende IT-Störungen schnell, direkt und proaktiv? Sind Ihre Kunden und Kundenkunden begeistert von der Performance Ihrer Online-Services? Können Sie die SLAs Ihrer externen Service-Provider in Echtzeit überwachen und rasch agieren? Stimmt das Verhältnis zwischen vorhandenen IT-Assets oder Cloud-Ressourcen und der Nutzung zu jedem Zeitpunkt bzw. können Sie bei Veränderungen kurzfristig reagieren? Kann sich Ihr Service Desk auf die wirklich wichtigen Tickets konzentrieren und diese System-gestützt schnell bearbeiten – bei hoher Service-Qualität?
Mit einer integrierten und professionellen Monitoring-Gesamtlösung können Sie auf jede dieser Fragen mit JA antworten – und damit Kosten und Risiken minimieren.
Digitale Services in der öffentlichen Verwaltung? In Deutschland? Das ist schwer vorstellbar. Denn...
Alarm Management IT Monitoring IT Service Alerting
Die IT-Organisationen größerer Unternehmen sehen sich täglich mit 5 kritischen und etwa 80 weniger...
Chatbots und IT-Service sind wie geschaffen füreinander. Denn damit können Sie IT-Probleme direkt...